Architecture
Fuego consists of a continuous integration system, along with some pre-packaged test programs and a shell-based test harness, running in a Docker container.
Fuego = (Jenkins + abstraction scripts + pre-packed tests)
inside a containerHere's a diagram with an overview of Fuego elements:
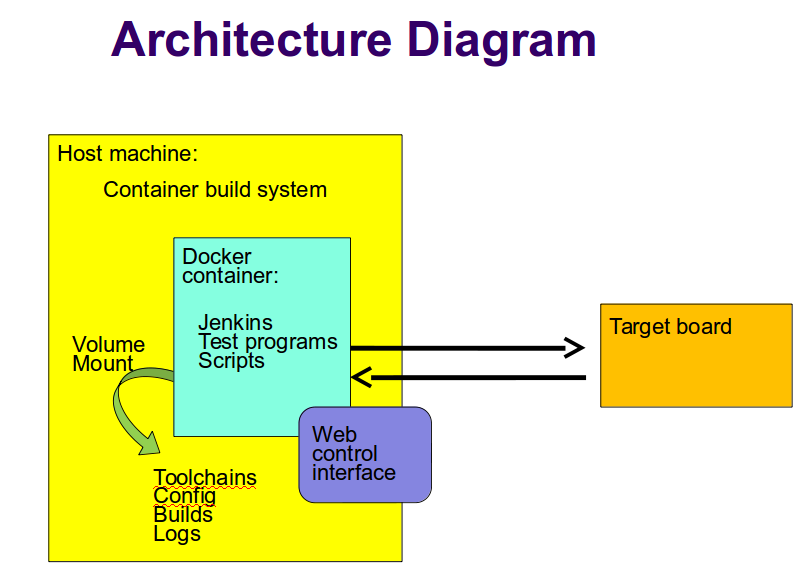
Major elements [edit section]
The major elements in the Fuego architecture are:
- host system
- container build system
- fuego container instance
- Jenkins continuous integration system
- web-based user interface (web server on port 8080)
- plugins
- test programs
- abstraction scripts (test scripts)
- build environment (not shown in the diagram above)
- Jenkins continuous integration system
- target system
- web client, for interaction with the system
Jenkins [edit section]
The main interface for Fuego is provided by the Jenkins continuous integration system.The basic function of Jenkins is to automatically launch test jobs, usually in response to changes in the software. However, it can launch test jobs based on a variety of triggers, including when a user manually schedules a test to run.
Jenkins is too big a system to describe in detail here, but it has many features and is very popular. It has an ecosystem of plugins for all kinds of extended functionality, such as integration with different source code management systems, results plotting, e-mail notifications of regressions, and more.
Fuego installs several plugins that are used by various aspects of the system.
Jenkins is used to:
- Start tests
- Schedule tests for automatic execution
- Shows test results (particularly over time)
- Flag regressions in test results
Note that the interface between Jenkins and the test programs is provided by a set of scripts (one per test, along with a set of scripts that comprise the core of the system) written in shell script language.
The interface between Jenkins and these core scripts is documented at Core interfaces.
This overall architecture means that when items are added into the system (for example boards, toolchains, or tests), information has to be supplied to both systems (the Jenkins system and the core script system).
Pre-packaged tests [edit section]
Abstraction scripts [edit section]
Fuego uses a set of shell script fragments to support abstractions for- building test programs from source,
- deploying them to target (installing them)
- executing the tests
- copy files to and from the target
- reading the test log
- parsing the log to determine pass or fail conditions for tests
- parsing the log for results to display in charts
Container [edit section]
By default, Fuego runs inside a Docker container. This provides two benefits:
- It makes it easy to run the system on a variety of different Linux distributions
- It makes the build environment for the test programs consistent
Hardware configuration [edit section]
Fuego supports testing of embedded Linux by fully supporting a host/target configuration for building, deploying and executing tests.Many Linux test systems assume that the system-under-test is a full desktop or server system, with sufficient horsepower to build tests and run them locally. Fuego assumes the opposite - that embedded targets will be underpowered and may not have the normal complement of utilities and tools available for performing tests
Jenkins operations [edit section]
How does Jenkins work?- When the a test is initiated, Jenkins starts a slave process to run the test
- Jenkins records stdout from slave process
- the slave (slave.jar) runs a script specified in the config.xml for each test
- this script sources functions from the scripts and overlays directory of Fuego, and does the actual building, deploying and test executing
- Also, Jenkins calls the post_test operation to accumulate logs and determine status
- while a test is running, Jenkins accumulates the log output from the generated test script and displays it to the user (if they are watching the console log)
- Jenkins provides a web UI for browsing the target boards, tests, and test results (runs), and displaying graphs for benchmark data
Fuego operations [edit section]
How do the Fuego scripts work?
Test execution [edit section]
- each test has a core script, that defines a few functions specific to that test (see below)
- upon execution, this core script expands itself using an overlay generator
- the overlay generator is creates a customized script for this test run
- the expanded script is created in /userdata/work
- the expanded script is called <target>_prolog.sh
- the overlay generator is called ovgen.py
- the expanded script runs on the host, and uses fuego functions to perform different phases of the test
- for a detailed flow graph of normal test execution see: test execution flow outline
expanded script generation [edit section]
- the generator takes the following as input:
- environment variables passed by Jenkins
- board file for the target (selected with BOARD_OVERLAY)
- tools.sh (vars from tools.sh are selected with PLATFORM, from the board file)
- the distribution file, and (selected with DISTRIB)
- the testplans for the test (selected with TESTPLAN)
- test specs for the test
- the generator produces the expanded script
- the expanded script is in /userdata/work/<target>_prolog.sh
- this generation happens on the host, inside the docker container
- the expanded script has functions which are available to be called by the base test script
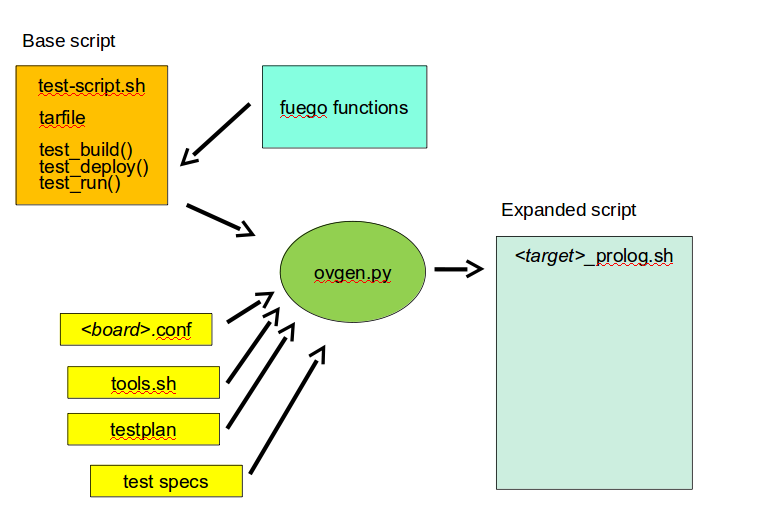
- input descriptions:
- the board file has variables defining attributes of the board, like the platform, network address, method of accessing the board, etc.
- tools.sh has variables which are used for identifying the toolchain used to build binary test programs
- it uses the PLATFORM variable to select the set of variables to define
- a testplan lists multiple tests to run
- it specifies a test name and spec for each one
- a spec files hold the a set of variable declarations which are used by the tests themselves. These are put into environment variables on the target.
- ovgen.py reads the plans, board files, distrib files and specs, and produces a single prolog.sh file that has all the information for the test
- Each test in the system has a fuego shell script
- this is usually named <test>-script.sh, but may have other names
- the <test>-script.sh file declares the tarfile for the test, and has functions for: test_build(), test_deploy() and test_run()
- the test script is run (mostly) on host (in the container)
- tarball has the tarfile
- test_build() has commands (which run in the container) to compile the test program
- test_deploy() has commands to put the test programs on the target
- test_run() has commands to define variables, execute the actual test, and log the results.
- the test program is run on the target
- this is the actual test program that runs and produces a result
fuego test phases [edit section]
A test execution in fuego runs through several phases, some of which are optional, depending on the test.The test phases are:
- pre_test
- build
- deploy
- run
- get_testlog
- processing
- post_test
Each of these are described below the diagram.
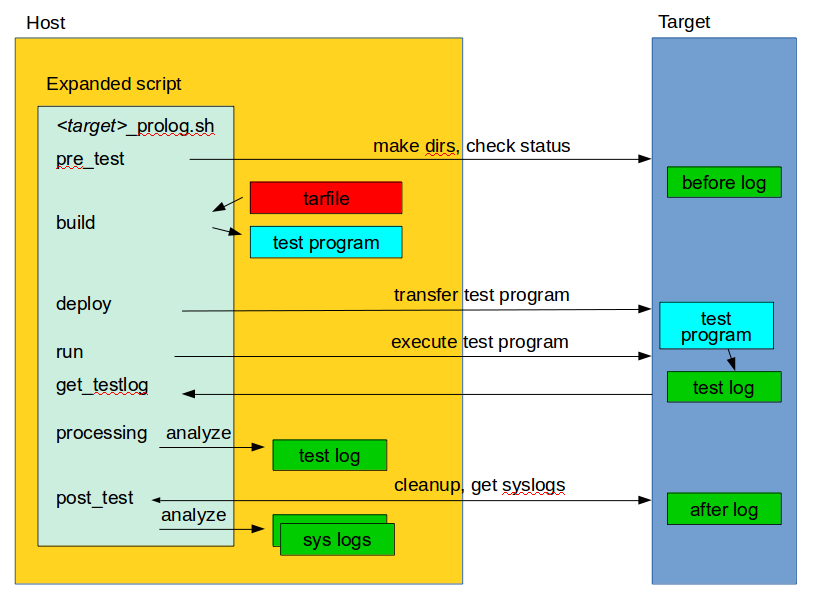
pre_test [edit section]
The pre_test phase consists of making sure the target is alive, and preparing the workspace for the test. In this phase test directories are created, and the firmware (a string describing the software on the target) are collected.The 'before' syslog is created, and filesystems are synced and buffer caches dropped, in preparation for any filesystem tests.
build [edit section]
During this phase, the test program source is installed on the host (inside the container), and the software for the test is actually built. The toolchain specified by PLATFORM is used to build the software.This phase is split into multiple parts:
- pre_build - build workspace is created, a build lock is acquired and the tarball is unpacked
- unpack is called during pre_build
- test_build - this function, from the base script, is called
- usually this consists of 'make', or 'configure ; make'
- post_build - (empty for now)
deploy [edit section]
The purpose of this phase is to copy the test programs, and any required supporting files, to the target.This consists of 3 sub-phases:
- pre_deploy - cd's to the build directory
- test_deploy - the base script's 'test_deploy' function is called.
- Usually this consists of tarring up needed files, copying them to the target with 'put', and then extracting them there
- Items should be placed in the directory $FUEGO_HOME/fuego.$TESTDIR/ directory on the target
- post_deploy - removes the build lock
run [edit section]
In this phase the test program on the target is actually executed.This executes the 'test_run' function defined in the base script for the test, which can consist of anything. Usually, however, it runs the test program with any needed parameters (as specified by the test specs and test plans).
The test execution is usually performed with the 'report' command, which will collect the standard out from the command execution on the target, and save that as the testlog for the test. Note that the testlog is saved on the target, but not yet transferred to the host.
get_testlog [edit section]
In this phase, the test log is retrieved from the target and stored on the host. Note that for functional tests, this is a separate step. But for benchmark tests, this operation in included in the processing phase. (This is an internal detail that should not be a consideration for most test developers.)
processing [edit section]
In the processing phase of the test, the results from the test log are evaluated. The test_processing function of the base test script is called.For functional tests:
Usually, this phases consists of one or more calls to log_compare, to determine if a particular string occurs in the testlog. This phase determines whether the test passed or failed, and the expanded test script indicates this to the Jenkins interface.
For benchmarking tests:
This phase consists of parsing the testlog, using parser.py, and also running dataload.py.
post_test [edit section]
In this phase, cleanup of the test area is performed on the target, and system logs are downloaded from the target. A final analysis is done on the system logs.
phase relation to base script functions [edit section]
Some of the phases are automatically performed by fuego, and some end up calling a routine in the base script (or use data from the base script) to perform their actions. This table shows the relation between the phases and the data and routines that should be defined in the base script.It also shows the most common command utilized by base script functions for this phase.
| phase ^ | relationship to base script ^ | common operations ^ |
| pre_test | (none) | |
| build | uses the 'tarfile' definition, calls 'test_build' | patch, configure, make |
| deploy | calls 'test_deploy' | put |
| run | calls 'test_run' | assert_define, report |
| get_testlog | (none) | |
| processing | calls 'test_processing' | log_compare |
| post_test | (none) |
other scripts and programs [edit section]
- parser.py is used for benchmark tests
- it is run against the test log, on the host
- it extracts the values from the test log and puts them in a normalized format
- in the functions in the distribution file, cmd: means to perform the command on the target
Data Files [edit section]
There are data files with definitions for several things in the system.The Jenkins interface needs to know about boards, running test processes (slaves), test definitions, and test results.
The fuego core needs to know about test definitions, boards, platforms (SDKS), test plans, and test specs.
The core executes the test script for a , in sequence, build the test program, bundle the test programs for the target, and build a custom shell script for a particular test run, execute that script.
The custom shell script should:
- build the test program
- deploy the test bundle to the target
- execute the tests
- read the log data from the test
The custom shell script can handle host/target tests (because it runs on the host).
(That is, tests that involve actions on both the host and target.
to add a new test, the user defines several files and puts them into /home/jenkins/tests
The jenkins front end scans this directory for tests to show in the user interface. However, each test has to have a front-end entry to allow Jenkins to execute it. This front-end entry specifies the test script for the test.
Roles [edit section]
Human roles:- test program author - person who creates a new standalone test program
- test integrator - person who integrates a standalone test into fuego
- fuego developer - person who modifies Jenkins to support more test scenarios or additional features
- tester - person who executes tests and evaluates results
More Details [edit section]
specific questions to answer [edit section]
What happens when you click on the "run test" button:- what processes start on the host
- what interface is used between xxx_prolog.sh and the jenkins processes
- stop appears to be by issuing "http://localhost:8080/stop"
Boards are defined in Jenkins in:/var/lib/jenkins/config.xml
- this is linked to /userdata/conf/config.xml which is tied to jta-public/userdata/conf/config.xml in the host filesystem
- each board in config.xml has an xml section inside a <slave> element.
- The values in this xml section are defined using the Jenkins web interface
- a few environment variables are important:
- BOARD_OVERLAY - this refers to the <target>.board file.
- An example is: boards/bbb.board
- DISTRIB - this refers to the type of distribution.
- Currently, only distribs/nologger.dist is supported
- BOARD_OVERLAY - this refers to the <target>.board file.
- a few environment variables are important:
These two environment variables are passed to the test agent, which is always "java -jar /home/jenkins/slave.jar"
- Who calls ovgen.py - it is included indirectly, when the base script sources the shell script for it's test type (functional.sh or benchmark.sh)
Jenkins calls:
- java -jar /home/jenkins/slave.jar
- with variables:
- Device
- Reboot
- Rebuild
- Target_Cleanup
- TESTPLAN
- with variables:
- the Test Run section of the job for a test configuration has a command with the following shell commands:
if [ ! -d "$FUEGO_LOGS_PATH/$JOB_NAME" ]; then mkdir -p "$FUEGO_LOGS_PATH/$JOB_NAME"; fi echo $TESTPLAN >$FUEGO_LOGS_PATH/$JOB_NAME/last_used_testplan; TESTPLAN=testplans/$TESTPLAN.json source $FUEGO_TESTS_PATH/$JOB_NAME/aim7.sh
Some Jenkins notes: Jenkins stores its configuration in plain files under JENKINS_HOME You can edit the data in these files using the web interface, or from the command line using manual editing (and have the changes take affect at runtime by selecting "Reload configuration from disk".
By default, Jenkins assumes you are doing a continuous integration action of "build the product, then test the product". It has default support for Java projects.
Fuego seems to use distributed builds (configured in a master/slave fashion).
Jenkins home has (from 2007 docs):
- config.xml - has stuff for the main user interface
- *.xml
- fingerprints - directory for artifact fingerprints
- jobs
- <JOBNAME>
- config.xml
- workspace
- latest
- builds
- <ID>
- build.xml
- log
- changelog.xml
- <JOBNAME>
The docker container interfaces to the outside host filesystem via the following links:
- /var/lib/jenkins/logs -> /userdata/logs -> fuego/userdata/logs
- /home/jenkins/logs ->/userdata/logs -> fuego/userdata/logs
- /var/lib/jenkins/config.xml -> /userdata/conf/config.xml -> fuego/userdata/conf/config.xml
What are all the fields in the "configure target" dialog: Specifically:
- where is "Description" used?
- what is "# of executors"?
- how is "Remote FS root" used?
- is this a path inside the Fuego container, or on the target?
- I presume that the slave program is actually 'xxx_prolog.sh', which runs on host, and that /tmp/dev-slave1 would be where builds for the target would occur.
- is this a path inside the Fuego container, or on the target?
- what are Labels used for? as tags for grouping builds
- Launch method: Fuego uses the Jenkins option "Launch slave via execution of command on the Master"
The command is "java -jar /home/jenkins/slave.jar"
- NOTE: slave.jar comes from jta-core git repository, under engine/slave.jar
The fuego-core repository has:
engine
overlays - has the base classes for fuego functions
base - has core shell functions
boards - has board definition files
testplans - has json files for parameter specifications
distribs - has shell functions related to the distro
test_specs - has json files with parameter specifications
Benchmark.foo.spec
Functional.bar.spec
scripts - has fuego scripts and programs
(things like overlahs.sh, loggen.py, parser/common.py, ovgen.py, etc.
slave.jar - ???
test_run.properties - file containing some Jenkins variables
tests - has a directory for each test
Benchmark.foo
Functional.bar
LTP
etc.
jobs - has information about jobs, including config.xml (front-end test definition)
plugins-conf
What is groovy:
- an interpreted language for Java, used by the scriptler plugin to extend Jenkins
What plugins are installed with Jenkins in the JTA configuration?
- Jenkins Mailer, LDPA, External Monitor Job Type, PAM, Ant, Javadoc
- Jenkins Environment File (special)
- Credentials, SSH Credentials, Jenkins SSH Slags, SSH Agent
- Git Client, Subversion, Token Macro, Maven Integration, CVS
- Parameterized Trigger (special)
- Git, Groovy Label Assignment Extended Choie Parameter
- Rebuilder...
- Groovy Postbuild, ez-templates, HTML Publisher (special)
- JTA Benchmark show plot plugin (special)
- Log Parser Plugin (special)
- Dashboard view (special)
- Compact Columns (special)
- Jenkins Dynamic Parameter (special)
- flot (special) - benchmark graphs plotting plug-in for Fuego
Which of these did Cogent write?
- the flot plugin (not flot itself)
What scriptler scripts are included in JTA?
- getTargets
- getTestplans
- getTests
What language are scriptler scripts in?
- Groovy
What is the Maven plugin for Jenkins?
- Maven is an apache project to build and manage Java projects
- I don't think the plugin is needed for Fuego
Jenkins refers to a "slave" - what does this mean?
- it refers to a sub-process that can be delegated work. Roughly speaking, Fuego uses the term 'target' instead of 'slave', and modifies the Jenkins interface to support this.
How the tests work [edit section]
A simple test that requires no building is Functional.bc- the test script and test program source are found in the directory: /home/jenkins/tests/Functional.bc
This runs a shell script on target to test the 'bc' program.
Functional.bc has the files:
bc-script.sh
declares "tarball=bc-script.tar.gz"
defines shell functions:
test_build - calls 'echo' (does nothing)
test_deploy - calls 'put bc-device.sh'
test_run - calls 'assert_define', 'report'
report references bc-device.sh
test_processing - calls 'log_compare'
looking for "OK"
sources $JTA_SCRIPTS_PATH/functional.sh
bc-script.tar.gz
bc-script/bc-device.sh
Variables used (in bc-script.sh):
FUEGO_HOME TESTDIR FUNCTIONAL_BC_EXPR FUNCTIONAL_BC_RESULT
A simple test that requires simple building: Functional.synctest
This test tries to call fsync to write data to a file, but is interupted with a kill command during the fsync(). If the child dies before the fsync() completes, it is considered success.
It requires shared memory (shmget, shmat) and semaphore IPC (semget and semctl) support in the kernel.
Functional synctest has the files:
synctest.sh
declares "tarball=synctest.tar.gz"
defines shell functions:
test_build - calls 'make'
test_deploy - calls 'put'
test_run - calls 'assert_define', hd_test_mount_prepare, and 'report'
test_processing - calls 'log_compare'
looking for "PASS : sync interrupted"
sources $JTA_SCRIPTS_PATH/functional.sh
synctest.tar.gz
synctest/synctest.c
synctest/Makefile
synctest_p.log
has "PASS : sync interrupted"
Variables used (by synctest.sh)
CFLAGS
LDFLAGS
CC
LD
FUEGO_HOME
TESTDIR
FUNCTIONAL_SYNCTEST_MOUNT_BLOCKDEV
FUNCTIONAL_SYNCTEST_MOUNT_POINT
FUNCTIONAL_SYNCTEST_LEN
FUNCTIONAL_SYNCTEST_LOOP
(NOTE: could be improved by checking for CONFIG_SYSVIPC in /proc/config.gz
to verify that the required kernel features are present)
MOUNT_BLOCKDEV and MOUNT_POINT are used by 'hd_test_mount_prepare'
but are prefaced with FUNCTIONAL_SYNCTEST or BENCHMARK_BONNIE
-------
from clicking "Run Test", to executing code on the target...
config.xml has the slave command: /home/jenkins/slave.jar
-> which is a link to /home/jenkins/jta/engine/slave.jar
overlays.sh has "run_python $OF_OVGEN ..."
where OF_OVGEN is set to "$JTA_SCRIPTS_PATH/ovgen/ovgen.py"
How is overlays.sh called?
it is sourced by /home/jenkins/scripts/benchmarks.sh and
/home/jenkins/scripts/functional.sh
functional.sh is sourced by each Funcational.foo script.
For Functional.synctest:
{{{
Functional.synctest/config.xml
for the attribute <hudson.tasks.Shell> (in <builders>)
<command>....
souce $JTA_TESTS_PATH/$JOB_NAME/synctest.sh</command>
synctest.sh
'. $JTA_SCRIPTS_PATH/functional.sh'
'source $JTA_SCRIPTS_PATH/overlays.sh'
'set_overlay_vars'
(in overlays.sh)
run_python $OF_OVGEN ($JTA_SCRIPTS_PATH/ovgen/ovgen.py) ...
$OF_OUTPUT_FILE ($JTA_SCRIPTS_PATH/work/${NODE_NAME}_prolog.sh)
generate xxx_prolog.sh
SOURCE xxx_prolog.sh
functions.sh pre_test()
functions.sh build()
... test_build()
functions.sh deploy()
test_run()
assert_define()
functions.sh report()
NOTES about ovgen.py [edit section]
What does this program do?Here is a sample command line from a test console output:
python /home/jenkins/scripts/ovgen/ovgen.py \ --classdir /home/jenkins/overlays//base \ --ovfiles /home/jenkins/overlays//distribs/nologger.dist /home/jenkins/overlays//boards/bbb.board \ --testplan /home/jenkins/overlays//testplans/testplan_default.json \ --specdir /home/jenkins/overlays//test_specs/ \ --output /home/jenkins/work/bbb_prolog.sh
So, ovgen.py takes a classdir, a list of ovfiles a testplan and a specdir, and produces a xxx_prolog.sh file, which is then sourced by the main test script
Here is information about ovgen.py source:
Classes: OFClass OFLayer TestSpecs
Functions: parseOFVars - parse Overlay Framework variables and definitions parseVars - parse variables definitions parseFunctionBodyName parseFunction baseParseFunction parseBaseFile parseBaseDir parseInherit parseInclude parseLayerVarOverride parseLayerFuncOverride parseLayerVarDefinition parseLayerCapList - look for BOARD.CAP_LIST parseOverrideFile generateProlog generateSpec parseGenTestPlan parseSpec parseSpecDir run
Sample generated test script [edit section]
bbb_prolog.sh is 195 lines, and has the following vars and functions:
from class:base-distrib: ov_get_firmware() ov_rootfs_kill() ov_rootfs_drop_caches() ov_rootfs_oom() ov_rootfs_sync() ov_rootfs_reboot() ov_rootfs_state() ov_logger() ov_rootfs_logread() from class:base-board: LTP_OPEN_POSIX_SUBTEST_COUNT_POS MMC_DEV SRV_IP SATA_DEV ... JTA_HOME IPADDR PLATFORM="" LOGIN PASSWORD TRANSPORT ov_transport_cmd() ov_transport_put() ov_transport_get() from class:base-params: DEVICE PATH SSH SCP from class:base-funcs: default_target_route_setup() from testplan:default: BENCHMARK_DHRYSTONE_LOOPS BENCHMARK_<TESTNAME>_<VARNAME> ... FUNCTIONAL_<TESTNAME>_<VARNAME>
Logs [edit section]
When a test is executed, several different kinds of logs are generated: devlog, systemlogs, the testlogs, and the console log.
created by Jenkins [edit section]
- console log
- this is located in /var/lib/jenkins/jobs/<test_name>/builds/<build_id>/log
- is has the output from running the test script (on the host)
created by expanded script [edit section]
- devlog has a list of commands run on the target during the test
- located in /userdata/logs/<test_name>/devlog/<target>.<build_id>.txt
- systemlogs has /var/log/messages before and after the test run, from the target
- located in /userdata/logs/<test_name>/systemlogs
- there is a 'before' and 'after' log for each test run
- testlogs has the actual output from the test program on the target
- this is completely dependent on what the test program outputs
- located in /userdata/logs/<test_name>/testlog/<target>.<build_id>.log
- this is the 'raw' log
- <target>.<build_id>.{4}.log has the 'parsed' log
- in the case of Functional.bc, this is "OK"
Core scripts [edit section]
The main scripts that are sourced by a test script are:- benchmarks.sh
- functional.sh
- stress.sh
- test.sh
These have the same pattern of operations in them:
- load overlays and set_overlay vars
- source functions.sh and reports.sh
- pre_test $TEST_DIR
- build
- deploy
- test_run
- set_testres_file, bench_processing, check_create_logrun (if a benchmark)
- get_testlog $TESTDIR, test_processing (if a functional test)
- get_testlog $TESTDIR (if a stress test)
- test_processing (if a regular test)
functions available to test scripts: See Test Script APIs
notes about benchmark tests [edit section]
Benchmark tests must provide a reference.log file. This has a special syntax recognized by parser.py and the common.py library.It consists of a series of lines, showing a name, test and value The syntax is: [<var-name>|<test>] <value>
An example is: [dhrystones|ge] 1
This says: the test is OK, if the value of 'dhrystones' is greater than or equal to 1.
(NOTE: this is an extremely weird syntax)
A reference.log file can have multiple tests.
Benchmark tests must provide a parser.py file, which extracts the (single value)? from the log data.
It does this by doing the following: import common as plib f = open(plib.CUR_LOG) lines = f.readlines() ((parse the data)) create a dictionary with a key and value, where the key matches the string in the reference.log file
The parser.py program builds a dictionary of values by parsing the log from the test (basically the test output). It then sends the dictionary, and the pattern for matching the reference log test criteria to the routine: common.py:process_data()
It defines ref_section_pat, and passes that to process_data() Here are the different patterns for ref_section_pat: 9 "\[[\w]+.[gle]{2}\]" 1 "\[\w*.[gle]{2}\]" 1 "^\[[\d\w_ .]+.[gle]{2}\]" 1 "^\[[\d\w_.-]+.[gle]{2}\]" 1 "^\[[\w\d&._/()]+.[gle]{2}\]" 4 "^\[[\w\d._]+.[gle]{2}\]" 2 "^\[[\w\d\s_.-]+.[gle]{2}\]" 3 "^\[[\w\d_ ./]+.[gle]{2}\]" 5 "^\[[\w\d_ .]+.[gle]{2}\]" 1 "^\[[\w\d_\- .]+.[gle]{2}\]" 1 "^\[[\w]+.[gle]{2}\]" 1 "^\[[\w_ .]+.[gle]{2}\]" Why are so many different ones needed?? Why couldn't the syntax be: <var-name> <test> <value> on one line?
How is benchmarking graphing done? [edit section]
See Benchmark parser notesdocker tips [edit section]
- show the running docker ID sudo docker ps
- attach another shell inside the container sudo docker exec -i -t <id> bash
- copy files to the container docker cp
- execute a command in the container docker exec
- access docker container using ssh
ssh user@<ip_addr> -p 2222
- sshd is running on 2222
config.xml usage [edit section]
- here is the output from inotifywait -m . (in /var/lib/jenkins) ./ CREATE atomic4455062987458667627.tmp ./ OPEN atomic4455062987458667627.tmp ./ CLOSE_WRITE,CLOSE atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ OPEN atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ MODIFY atomic4455062987458667627.tmp ./ CLOSE_WRITE,CLOSE atomic4455062987458667627.tmp ./ DELETE config.xml ./ MOVED_FROM atomic4455062987458667627.tmp ./ MOVED_TO config.xml ./ CREATE atomic7864701306964501324.tmp ./ OPEN atomic7864701306964501324.tmp ./ CLOSE_WRITE,CLOSE atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ OPEN atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ MODIFY atomic7864701306964501324.tmp ./ CLOSE_WRITE,CLOSE atomic7864701306964501324.tmp ./ DELETE config.xml ./ MOVED_FROM atomic7864701306964501324.tmp ./ MOVED_TO config.xml ./ CREATE atomic6253634889206863905.tmp ./ OPEN atomic6253634889206863905.tmp ./ CLOSE_WRITE,CLOSE atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ OPEN atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ MODIFY atomic6253634889206863905.tmp ./ CLOSE_WRITE,CLOSE atomic6253634889206863905.tmp ./ DELETE config.xml ./ MOVED_FROM atomic6253634889206863905.tmp ./ MOVED_TO config.xml
Here are the inotify events for a manual rename: ./ OPEN config.xml ./ ACCESS config.xml ./ CLOSE_NOWRITE,CLOSE config.xml ./ DELETE config.xml ./ CREATE config.xml